구글은 수백테라 이상의 정보를 유지하기 위해서 storage 가상화를 이용, 하드디스크를 하나의 논리적인 디스크로 묶어서 사용하고 있다. 이 가상화된 저장공간에는 캐쉬된 웹페이지 원본, 색인정보, Gmail, 이미지, 동영상, MapReduce 작업을 위한 중간작업파일들이 저장된다. 이러한 거대한 정보를 유지하기 위해서는 엄청난 양의 Disk가 필요할 것이다.
이번에 (2007/2) 구글은 100,000 개의 디스크드라이버를 운영하면서 분석한 정보를 토대로 작성된 논문을 공개했다. 상당히 흥미로운 내용을 담고 있어서 문서를 읽어 보기로 했다. 이 문서는 요약된 정보만을 제공한다. 자세한 내용은 문서를 직접 읽어보기 바란다.
원문 : http://labs.google.com/papers/disk_failures.pdf
100,000개의 하드디스크에 대한 몇년간의 정보를 수집하고 분석하는 것만해도 엄청난 작업일 것이다. 이를 위해서 구글은 다음과 같은 분석시스템을 구축했다.
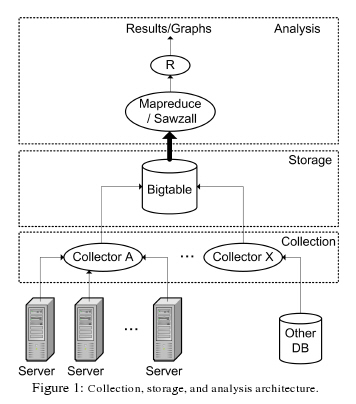
이러한 일은 SE의 업무분야일거라고 생각되는데, 위와 같은 분석시스템까지 갖추고 논문까지 만들어서 제출한다는 자체가 대단한 일이라고 생각된다. 우리나라에서의 SE의 위상은 ? SE라는 개념이 잡혀있는지도 궁금하다. 인터넷 강국과 인터넷 천국의 차이라고 생각한다.
시스템의 건강체크를 위한 하부구조를 만들기 위해서 모든 구글의 서버로 부터 전달되는 값을 저장하기 위한 분산 시스템이 준비된다. 이 분산 시스템은 분산 연산을 하기 위한 소프트웨어로 묶여 있다.
첫번째 계층은 Collection 계층으로 데이터를 수집하고 저장하기 위한 분산 저장환경을 유지한다. Collection의 소프트웨어는 구글서버에 설치되어 있는 시스템관리 데몬으로 부터 다양한 정보를 수집한다.
이 정보들은 광범위한 분석작업을 위해서 Bigtable로 압축이 된다. Bigtable는 필요없는 데이터를 제거하고 압축해서 빠른 데이터 분석이 가능하도록 만들어진 데이터 레이아웃이다. 1,000,000 명의 유저 데이터간의 유사성을 찾아내기 위해서 1,000,000 * 1,000,000의 2차원 테이블의 데이터를 분석해야 한다고 가정해보자. 유저의 도서구입 목록을 분석해서 비슷한 성향의 다른 유저가 즐겨보는 책을 추천해야 하는 시스템을 만들어야 할 경우에 사용될 수 있을 것이다. 아마존과 같은 세계규모의 온라인서점이라면, 이러한 류의 시스템이 갖추어져야 한다. Web2.0 서비스를 위한 기술이라는 점을 눈치챌 수 있을 것이다.
이렇게 Bigtable화 된 데이터는 Analysis계층에서 읽어들여서 분석을 하게 된다. 분석할 양이 방대하기 때문에, MapReduce 프로그래밍 모델을 적용한 엔진을 이용해서 분석을 하게 된다. 최종 결과물로 통계데이터와 그래프가 만들어지게 된다.
구글의 서비스를 위해서 사용되는 수십만개의 하드디스가 목표가 되었다. 이들은 대략 5400에서 7200rpm의 속도와 80G에서 400G까지의 크기를 가지는 ATA 하드디스크들로 이루어졌다. 모델도 다양해서 9개의 서로 다른 제조업체에서 만들어진 모델들이 사용되었다.
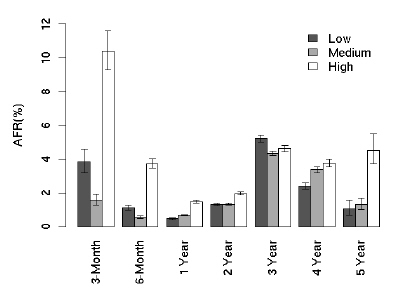
다음은 AFR결과다. 연간 오류발생율 이라고 해석하면 될거 같다. 일단 사용한지 2년째가 되는 시점부터 갑자기 오류발생율이 증가하는 것을 볼 수 있는데, 그뒤로는 딱히 별다른 움직임을 보이지 않는걸 알 수 있다. 특이한 점은 1년내에서 봤을 때, 처음 3개월때의 오류발생율이 가장 높고 1년까지 서서히 감소한다는 점이다.
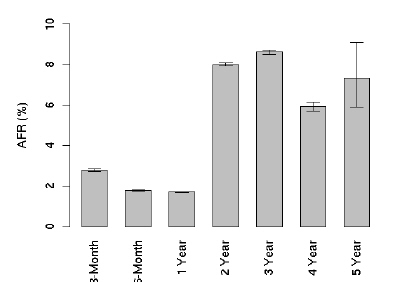
4년째 까지는 AFR의 편차가 작은데, 5년째부터 변동폭이 커지는걸 볼 수 있다. 이는 대략 5년 정도를 사용하게 되면, 하드디스크 제조업체에 따른 내구도의 차이 때문인거 같다. 실제 논문에도 제조업체별로 오류율에 있어서 차이점을 보여준다고 명시되어 있다. - 실제 업체를 공개하지는 않고 있다 -
또하나 특이한 점은 열심히 일한 하드디스크라고 해서 오류율이 증가하지는 않는다는 점이다. 아래의 그래프는 주간 read/write의 크기별, 오류율을 나타낸 것이다.
 놀고 있는 얘나 열심히 일한 얘나 별차이가 나지 않음을 보여주고 있다. 시스템 관리자 입장에서는 가능한 빡세게 돌리는게 여러모로 이익일거 같다. 단 처음 3개월은 워밍업 기간으로 생각하고 풀어줄 필요가 있을거 같다.
놀고 있는 얘나 열심히 일한 얘나 별차이가 나지 않음을 보여주고 있다. 시스템 관리자 입장에서는 가능한 빡세게 돌리는게 여러모로 이익일거 같다. 단 처음 3개월은 워밍업 기간으로 생각하고 풀어줄 필요가 있을거 같다.
온도가 높으면 고장율도 높아진다라는 건 당연하게 생각되고 있다. CPU는 어떤지 모르겠지만 하드디스크의 경우에는 별로 연관성이 없는거 같다.
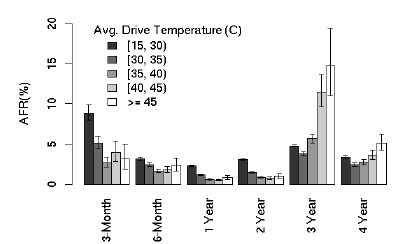
 오히려 예상과는 다르게 낮은 온도에서 더 높은 오류율을 보여주는걸 확인할 수 있다. 그래프 결과를 봐서는 40이하면 오류율에 큰 영향을 미치지 않는 것으로 보인다. 역시 어느정도 온도가 되어서 노글노글 해져야 부드럽게 도는게 아닌가 싶다.
오히려 예상과는 다르게 낮은 온도에서 더 높은 오류율을 보여주는걸 확인할 수 있다. 그래프 결과를 봐서는 40이하면 오류율에 큰 영향을 미치지 않는 것으로 보인다. 역시 어느정도 온도가 되어서 노글노글 해져야 부드럽게 도는게 아닌가 싶다.
전자 수준의 미시적인 현상으로 작동하는 CPU/메모리 등은 물리적특성이 중요한반면에 하드디스크는 적당한 워밍업, 적당한 온도, 적당한 활동 하에서 최적의 성능을 보여주는 기계적인 특성을 많이 타기 때문인거 같다.
- 출처: http://www.joinc.co.kr/modules/moniwiki/wiki.php/Site/Google/Service/Disk_Failure_Experience
우리가 알고 있는 하드 디스크 상식과 다른 점들이 있네요. 수용 여부는 각자 개인의 몫이겠죠.
이번에 (2007/2) 구글은 100,000 개의 디스크드라이버를 운영하면서 분석한 정보를 토대로 작성된 논문을 공개했다. 상당히 흥미로운 내용을 담고 있어서 문서를 읽어 보기로 했다. 이 문서는 요약된 정보만을 제공한다. 자세한 내용은 문서를 직접 읽어보기 바란다.
원문 : http://labs.google.com/papers/disk_failures.pdf
분석을 위해 사용된 기술
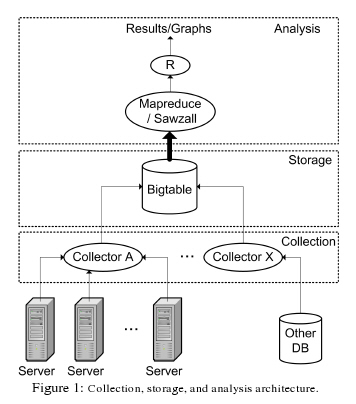
100,000개의 하드디스크에 대한 몇년간의 정보를 수집하고 분석하는 것만해도 엄청난 작업일 것이다. 이를 위해서 구글은 다음과 같은 분석시스템을 구축했다.
이러한 일은 SE의 업무분야일거라고 생각되는데, 위와 같은 분석시스템까지 갖추고 논문까지 만들어서 제출한다는 자체가 대단한 일이라고 생각된다. 우리나라에서의 SE의 위상은 ? SE라는 개념이 잡혀있는지도 궁금하다. 인터넷 강국과 인터넷 천국의 차이라고 생각한다.
시스템의 건강체크를 위한 하부구조를 만들기 위해서 모든 구글의 서버로 부터 전달되는 값을 저장하기 위한 분산 시스템이 준비된다. 이 분산 시스템은 분산 연산을 하기 위한 소프트웨어로 묶여 있다.
첫번째 계층은 Collection 계층으로 데이터를 수집하고 저장하기 위한 분산 저장환경을 유지한다. Collection의 소프트웨어는 구글서버에 설치되어 있는 시스템관리 데몬으로 부터 다양한 정보를 수집한다.
이 정보들은 광범위한 분석작업을 위해서 Bigtable로 압축이 된다. Bigtable는 필요없는 데이터를 제거하고 압축해서 빠른 데이터 분석이 가능하도록 만들어진 데이터 레이아웃이다. 1,000,000 명의 유저 데이터간의 유사성을 찾아내기 위해서 1,000,000 * 1,000,000의 2차원 테이블의 데이터를 분석해야 한다고 가정해보자. 유저의 도서구입 목록을 분석해서 비슷한 성향의 다른 유저가 즐겨보는 책을 추천해야 하는 시스템을 만들어야 할 경우에 사용될 수 있을 것이다. 아마존과 같은 세계규모의 온라인서점이라면, 이러한 류의 시스템이 갖추어져야 한다. Web2.0 서비스를 위한 기술이라는 점을 눈치챌 수 있을 것이다.
이렇게 Bigtable화 된 데이터는 Analysis계층에서 읽어들여서 분석을 하게 된다. 분석할 양이 방대하기 때문에, MapReduce 프로그래밍 모델을 적용한 엔진을 이용해서 분석을 하게 된다. 최종 결과물로 통계데이터와 그래프가 만들어지게 된다.
분석할 장비
구글의 서비스를 위해서 사용되는 수십만개의 하드디스가 목표가 되었다. 이들은 대략 5400에서 7200rpm의 속도와 80G에서 400G까지의 크기를 가지는 ATA 하드디스크들로 이루어졌다. 모델도 다양해서 9개의 서로 다른 제조업체에서 만들어진 모델들이 사용되었다.
결과
처음이 힘들다
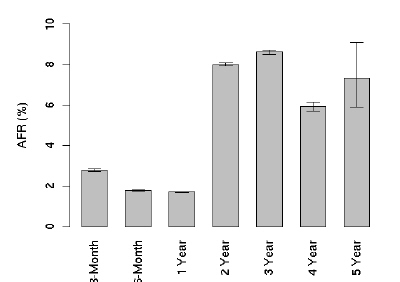
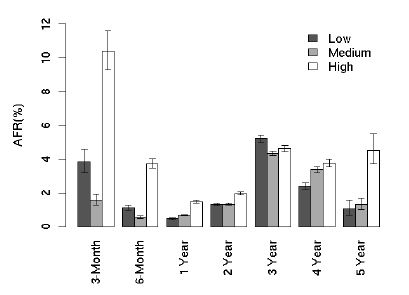
다음은 AFR결과다. 연간 오류발생율 이라고 해석하면 될거 같다. 일단 사용한지 2년째가 되는 시점부터 갑자기 오류발생율이 증가하는 것을 볼 수 있는데, 그뒤로는 딱히 별다른 움직임을 보이지 않는걸 알 수 있다. 특이한 점은 1년내에서 봤을 때, 처음 3개월때의 오류발생율이 가장 높고 1년까지 서서히 감소한다는 점이다.
| ||||||
4년째 까지는 AFR의 편차가 작은데, 5년째부터 변동폭이 커지는걸 볼 수 있다. 이는 대략 5년 정도를 사용하게 되면, 하드디스크 제조업체에 따른 내구도의 차이 때문인거 같다. 실제 논문에도 제조업체별로 오류율에 있어서 차이점을 보여준다고 명시되어 있다. - 실제 업체를 공개하지는 않고 있다 -
가능한 빡세게 굴려라
또하나 특이한 점은 열심히 일한 하드디스크라고 해서 오류율이 증가하지는 않는다는 점이다. 아래의 그래프는 주간 read/write의 크기별, 오류율을 나타낸 것이다.
냉방장치에 많은 돈을 들일 필요가 없다
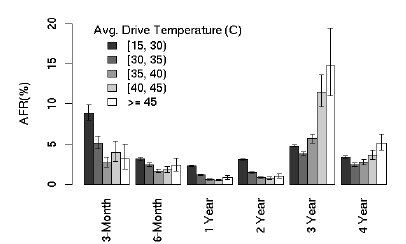
온도가 높으면 고장율도 높아진다라는 건 당연하게 생각되고 있다. CPU는 어떤지 모르겠지만 하드디스크의 경우에는 별로 연관성이 없는거 같다.
전자 수준의 미시적인 현상으로 작동하는 CPU/메모리 등은 물리적특성이 중요한반면에 하드디스크는 적당한 워밍업, 적당한 온도, 적당한 활동 하에서 최적의 성능을 보여주는 기계적인 특성을 많이 타기 때문인거 같다.
관련 링크
- 출처: http://www.joinc.co.kr/modules/moniwiki/wiki.php/Site/Google/Service/Disk_Failure_Experience
우리가 알고 있는 하드 디스크 상식과 다른 점들이 있네요. 수용 여부는 각자 개인의 몫이겠죠.
'컴퓨터 관련 > Hardwares' 카테고리의 다른 글
| Optimus Maximus Keyboard with 113 OLED Graphical Screen Keys (0) | 2008.06.20 |
|---|---|
| 파워 서플라이(Power Supply) 벤치마크 (0) | 2008.06.18 |
| ATI, NVIDIA 양사 그래픽 카드 분류하기 (3) | 2008.06.18 |
| DVI 케이블 종류 (0) | 2008.06.18 |
| 오픈프레임 LCD 해상도 관련 // 가독성 최적 화면 (2) | 2008.06.18 |